javascript
内存机制
js 内存空间分为栈(stack)、堆(heap)
栈:数据在栈内存中的存储与使用方式类似于数据结构中的堆栈数据结构,遵循后进先出的原则。
堆:
1 | var a1 = 0; // ``栈` |

基础数据类型:
NumberStringNullUndefinedBoolean
内存泄漏:
当内存存在无法被垃圾回收时,这种就叫内存泄漏
一段代码解释:
1 | // dom处理 |
如何解决:
- 手动清除引用
1 | let el = document.gteElementById("id"); |
- 使用弱引用-不计入 gc
- weakMap
- weakSet
垃圾回收机制
以 V8 为例, V8 将内存堆分为 新生代 区域, 老生代 区域,新生代存放生存时间短的对象,老生代存放生存时间长的对象。
新生代(1-8M)
- 算法:
Scavenge算法 - 原理:
- 新生代空间划分为两半,一半为对象区域,一半空闲区域
- 新增的对象进入对象区域,当对象区域被写满,则进行一次垃圾清除
- 将对象中的垃圾进行标记,存活的对象复制进入空闲区域
- 完成复制后,对象区域和空闲区域角色对换
- 对象晋升策略:
- 当对象经过两次回收还存在,则进入老生代
- 该对象空间超出区域25%,进入老生代
老生代
- 算法: 标记-清除
- 原理:
- 标记:从一组根元素开始,递归遍历这组根元素,遍历过程中能到达的元素称活动对象,没有到达的元素则为垃圾数据
- 清除
- 算法:标记-整理,清除垃圾后又大量不连续内存碎片
- 标记:与 标记清除一样
- 整理:让所有存活对象向内存一端移动
- 优化算法: 增量标记
- 原理:
- 为降低老生代垃圾回收时造成的全停顿卡顿
- 将任务拆解成小任务
- 与js引擎交替执行
调用栈
什么是调用栈?调用栈指的是管理函数调用的一种数据结构,栈一种容器,遵循先进后出,后进先出。
什么是栈溢出?
一段代码解释:
1 | function division(x, y) { |
函数递归调用,会出现压栈的行为,并不会弹出直到递归停止,当到达一定程度的数量,栈容器就会存在不够存放的情况,这种就叫栈溢出。
如何解决栈溢出?
- 利用异步任务优化(宏任务/微任务)
- 尾调用优化
内存的生命周期
JS 环境中分配的内存一般有如下生命周期:
_内存分配_:当我们申明变量、函数、对象的时候,系统会自动为他 们分配内存
_内存使用_:即读写内存,也就是使用变量、函数等
_内存回收_:使用完毕,由垃圾回收机制自动回收不再使用的内存
为了便于理解,我们使用一个简单的例子来解释这个周期。
var a = 20; // 在内存中给数值变量分配空间
alert(a + 100); // 使用内存
var a = null; // 使用完毕之后,释放内存空间
内存回收
在局部作用域中,当函数执行完毕,局部变量也就没有存在的必要了,因此垃圾收集器很容易做出判断并回收。但是全局变量什么时候需要自动释放内存空间则很难判断,因此在我们的开发中,需要尽量避免使用全局变量,以确保性能问题。
1 |
|
在上述代码中,当执行var f1 = fun1();的时候,执行环境会创建一个{name:'csa', age:24}这个对象,
当执行var f2 = fun2();的时候,执行环境会创建一个{name:'coder', age=2}这个对象
然后在下一次垃圾回收来临的时候,会释放{name:'csa', age:24}这个对象的内存,但并不会释放{name:'coder', age:2}这个对象的内存。
这就是因为在fun2()函数中将{name:'coder, age:2'}这个对象返回,并且将其引用赋值给了 f2变量,又由于f2这个对象属于全局变量,所以在页面没有卸载的情况下,f2所指向的对象{name:'coder', age:2}是不会被回收的。
标记清除算法
标记清除算法将“不再使用的对象”定义为“无法达到的对象”。简单来说,就是从根部(在 JS 中就是全局对象)出发定时扫描内存中的对象。凡是能从根部到达的对象,都是还需要使用的。那些无法由根部出发触及到的对象被标记为不再使用,稍后进行回收。
线程 VS 进程
进程是资源分配的最小单位,线程是CPU调度的最小单位
线程:多线程可以并行处理,但是线程是不能单独存在的,它是由进程来启动和管理的。
进程:一个进程就是一个程序的运行实例。详细的解释:启动一个程序的时候,操作系统回味该程序创建一块内存,用来存放代码、运行中的数据和一个执行任务的主线程
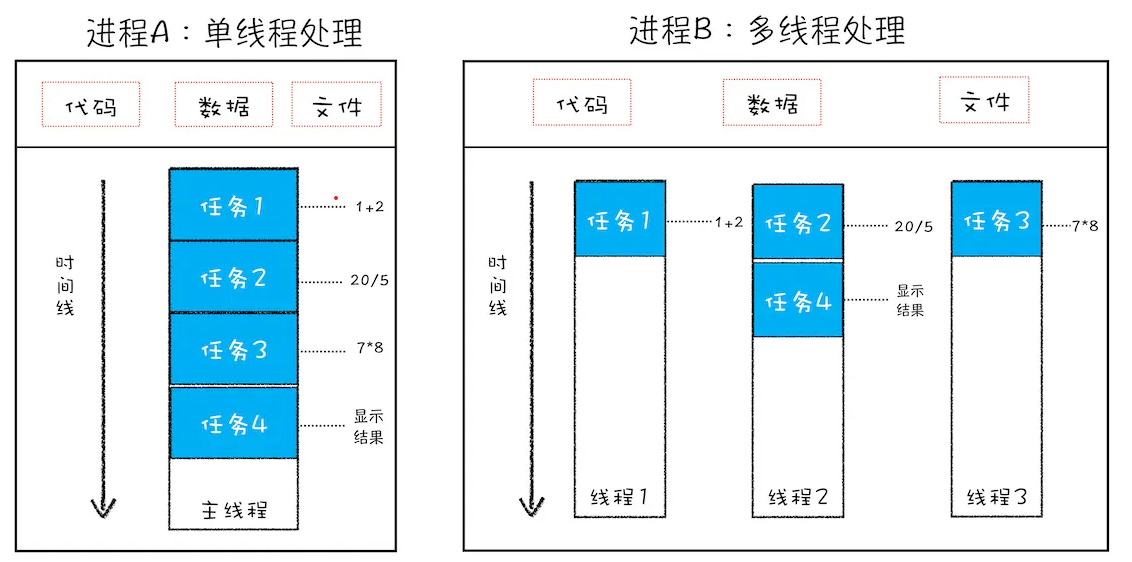
从图中可以看出线程依附于进程的,而进程中使用多线程并行处理能提升运算效率
进程和线程关系
- 进程中的任意一线程执行出错,都会导致整个进程的崩溃
- 线程之间共享进程中的数据
- 当一个进程关闭之后,操作系统会回收进程所占用的内存
- 进程之间的内容相互隔离,进行通讯需要使用用于进程通信(IPC)的机制了
Promise
解决了什么问题
promise解决的是异步编码风格的问题
- 异步编程的问题: 代码逻辑不连续
状态和方法
- 有几种状态
- pending
- fulfilled
- rejected
- 状态是否可变
状态不可变,resolve 之后不可 rejected,反之也是 - 有哪些方法,应用场景
- then
- race
- all
- catch
- reject
- allsettled
- any
async/await
catch 的捕获机制
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22function executor(resolve, reject) {
let rand = Math.random();
console.log(1)
console.log(rand)
if (rand > 0.5)
resolve()
else
reject()
}var p0 = new Promise(executor);
var p1 = p0.then((value) => {
console.log("succeed-1") return new Promise(executor)
})
var p3 = p1.then((value) => {
console.log("succeed-2") return new Promise(executor)
})
var p4 = p3.then((value) => {
console.log("succeed-3") return new Promise(executor)
})
p4.catch((error) => {
console.log("error")
})
console.log(2)当第一个出错时。p4 仍可以捕获到错误。这样就解决了每个任务都需要单独处理异常的问题
https://juejin.cn/post/6945319439772434469
思考
Promise 中为什么要引入微任务?
Promise 中是如何实现回调函数返回值穿透的?
Promise 出错后,是怎么通过“冒泡”传递给最后那个捕获异常的函数?
promise 部分实现
1 | class AlleyPromise { |
宏任务和微任务
- 宏任务
- 渲染事件(解析 DOM、计算布局、绘制)
- 用户交互事件(鼠标点击、滚动页面)
- js 脚本执行事件
- 网络请求完成事件
为了协调这些任务在主线程上稳定执行,引入了消息队列和事件循环机制,消息队列中的任务,就称为宏任务,消息队列中的任务是通过事件循环系统执行的
- 微任务
MutationObserver监控某 DOM 节点,通过 js 操作节点,节点发生变化,产生记录 DOM 变化的微任务使用
Promise,调用Promise.resolve()或者Promise.reject()产生微任务
执行脚本时,在宏任务执行过程中有时候会产生很多微任务,引擎会创建一个微任务队列,来存放微任务
微任务执行时机:
当前宏任务执行完成时,清空栈时,引擎检查微任务队列,按顺序执行队列中的任务
如果微任务队列执行中产生新的微任务,同样的会加到同个微任务队列中,循环执行。并不会推迟到下个宏任务中执行
结论:
微任务和宏任务时绑定的,每个宏任务在执行时会创建自己的微任务队列。
微任务时长会影响到当前宏任务的时长
在一个宏任务中,分别创建一个用于回调的宏任务和微任务,无论什么情况,微任务都早于宏任务。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17function fn(cb) {
console.log("谁先执行呢");
setTimeout(() => {
console.log("setTimeout执行");
cb();
});
new Promise((resolve) => {
resolve();
}).then(() => {
console.log("Promise执行");
cb();
});
}
fn(() => {});
// 谁先执行呢
// Promise执行
// setTimeout执行
1 | function executor(resolve, reject) { |
作用域
作用域,可以说是一套储存变量,访问变量的一套规则。指的是在这规则约束下,变量,函数,标识符可访问的区域。
js 作用域是词法作用域,一种静态作用域,静态作用域是代码编译阶段就决定好了,跟函数调用没有关系
有三种作用域:
全局作用域
函数作用域
块级作用域
作用域链
当作用域套作用域时,就形成了一条作用域链。
全局套函数
函数套函数
比如
1 | var b = 1; |
作用: 可让 a 函数可以访问到外部作用的变量,查找变量时的这条链就称为作用域链
但注意,作用域链时基于词法作用域的,也就是说作用域链的形成是代码书写阶段就已经确认下来
闭包
本质: 根据词法作用域,内部函数总是可以访问外部函数中声明的变量,当通过调用外部函数返回的内部函数时,外部执行完,但是内部函数引用外部函数的变量依然保存在内存,把这个些变量的结合称之为闭包。外部函数的闭包
执行上下文
执行上下文,是代码的执行环境。执行上下文可分为以下:
- 全局执行上下文:
- window 对象
- this
- 其他变量对象
- 函数执行上下文
- arguments
- this(不固定,根据谁引用就指向谁)
- 其他活动对象
- eval 执行上下文
分仔细还可以将执行上下文分为:
- 变量环境 (var 等定义的变量)
- 词法环境(let、const 等定义的变量)
- 作用域链(scope)
- this
执行上下文的生命周期:
创建阶段:
- 生成变量对象,安排内存
- 确认 this
- 确认作用域
执行阶段: - 变量赋值
变量提升,也就是在全局上下文创建阶段,给变量初始化安排内存,这时并未赋值
调用栈
先说结论,调用栈呢,是一种数据栈的数据结构管理执行上下文的,当执行环境执行多个函数时,也就是执行上下文执行调用函数时,会按顺序压入栈,执行到谁就先压入,遵循先进后出,执行完立即弹出。
从调用栈理解作用域:
我们所说,外部函数往往是访问不到内部函数的,这是为什么呢?
1 | function a() { |
调用栈的执行情况: 此时b位于栈顶,执行完直接弹出栈,b执行上下文被销毁,a自然是拿不到bb这个处于b作用域的变量
执行环境中的变量对象和活动对象
概念:每一个执行环境中都有一个与之关联的变量对象。如果这个环境是函数,那么将活动对象作为变量对象,活动对象最开始只包含一个变量,arguments对象。作用域链中的下一个比那辆对象来自外部环境
扩展:当执行流进入一个函数,函数的环境推入一个环境栈中,执行之后,再将环境弹出。
代码在一个环境中执行时,会创建变量对象的作用域链。作用域用途,是保证对执行环境有权访问的所有变量和函数的有序访问
this 那些事
this对象是在运行时基于函数的执行环境绑定的
- 默认绑定规则:
this指向window - 隐式绑定规则:函数被当作对象的方法调用时,
this指向对象(谁调用就指向谁) - 显示绑定规则:
call、apply、bind改变this指向
bind、apply、call 实现
1 | let obj = { |
原型对象和原型链
- 原型对象
概念:每一个构造函数中都有一个对象,
prototype,称为原型对象。构造函数、原型和实例的关系:原型对象
prototype都包含一个指向构造函数constructor的指针,而实例都包含一个指向原型对象的内部指针__proto__1
2
3
4
5function SuperType() {
this.property = true;
}
const superType = new SuperType();
console.log(superType.__proto__ === SuperType.prototype); // true
- 原型链
假设,让A的原型对象prototype等于另一个类型B的实例,此时A原型对象prototype将包含一个指向B原型的指针__proto__,相应的,B原型中也包含着一个指向另一个构造函数的指针。假如,又让C的原型对象prototype等于A的实例,如此层层递进,就构成了实例与原型的链条,这就是原型链的基本概念
1 | function SuperType() { |
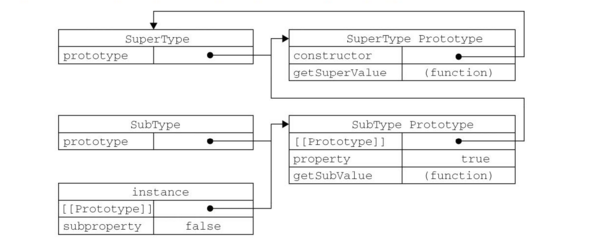
原型链的基本思想是利用原型让一个引用类型继承另一个引用类型的属性和方法
继承
原型链继承
1 | function Child() { |
缺点: 子共用同个属性方法,同个引用类型
借用构造函数继承
1 | function Child() { |
解决了原型链继承方法缺点
缺点: 子获取不到父原型上的属性方法
组合继承
1 | function Child() { |
解决了借用构造函数获取不到父类原型上的属性方法
缺点: 调用了两次父类
原型式继承
1 | const child = { |
缺点: 虽然简洁,但是同样存在引用同个引用问题
寄生式继承
与原型式差不多,只不过多了可以扩展父类的方法
寄生组合式继承
1 |
|
最优继承方式
new 实现
- 创建空对象
obj= {} this指向新对象,并执行构造函数,并获取返回结果- 设置原型链,新对象原型对象指向构造函数
prototype - 判断构造函数返回结果是否为对象,是则返回,否则返回由
new创建的对象a
1 | function myNew() { |
instanceOf 实现
1 | function A() {} |
解释性语言和编译性语言
编译性语言(C/GO...),在程序运行之前要经过编译器编译,编译后机器保留机器能读懂的二进制文件,当程序运行的时候直接运行二进制,不需重新编译解释性语言(JS/Python..),在每次运行时都要经过解释器动态解释和运行
编译器和解释器原理: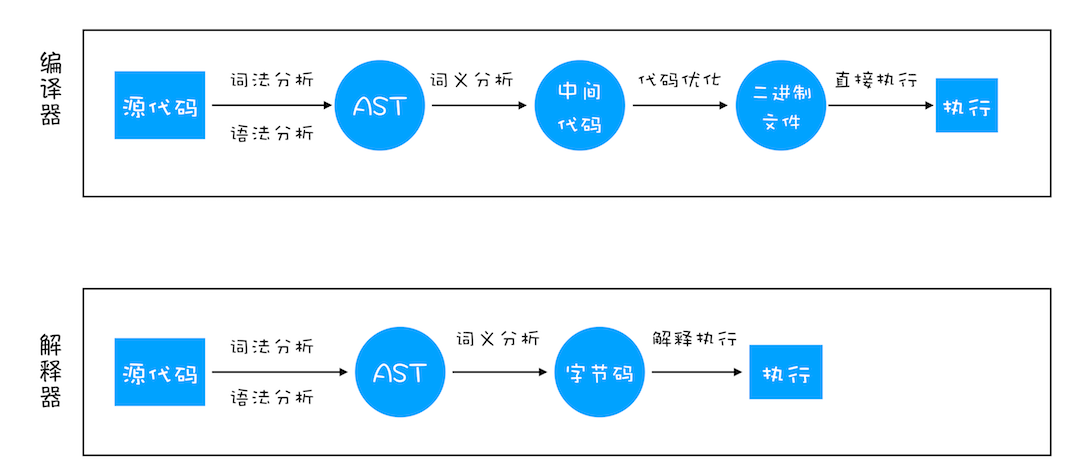
如何执行 JS
JIT(即时编译 just in time)技术:
热点代码会执行编译。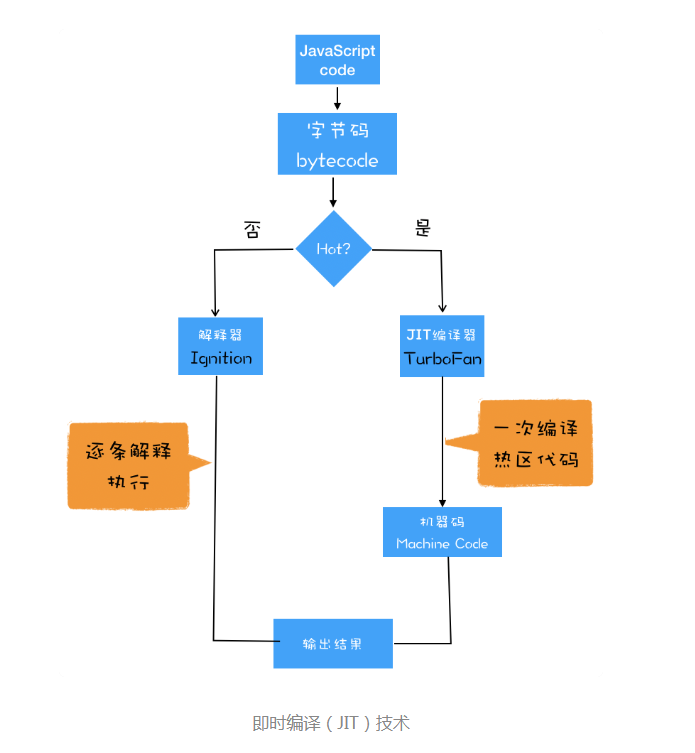
- 逐行解逐行执行
- 热点区一次性编译(JIT)
字节码需要解释器转换成机器码才能执行
ps: 机器码所需内存比字节码大,但是执行速度快,
模块化
- CommonJS
- ESM
- AMD
- UMD
ES7
- Array.prototype.includes()
- Math.pow()
ES8
- async/await
- Object.values()
- Object.entries()
ES9
- 异步迭代
1 | for (let i of array) { |
- Promise.finally()
- Rest/Spread 属性
ES10
- flat()
- flatMap()
- Object.fromEntries()
- BigInt
ES11
- 空值处理 ??
- 可选链 ?
- Promise.allSettled
- Dynamic import
隐式转换
js 的隐式转换会发生在运算过程,比如+ - * / == < >;
简单类型:
一般的情况会将两侧转换会数字再进行运算:
比如:
1 | 1 + false; // 1 |
特殊情况:
当 + 号 两个存在字符串,两边会直接当作字符串运算
1 | 1 + "1"; // 11 |
引用类型:
会执行ToPrimitive运算,默认执行 valueOf -> toString 转换基本类型运算
1 | let a = {}; |
强类型 和 弱类型
强类型: 变量之间有严格的规定类型,不同类型之间不可随意转换。 let a = 1; let b = 'string'; 不可将 b 赋值给数字类型的 a , a = b,除非强制转换弱类型: 变量之间没有约束,不同类型之间可以随意转换
静态类型 和 动态类型
静态类型:在编译阶段就确定了所有变量的类型动态类型:在执行阶段确定变量类型